ИТ-инфраструктура
Инфраструктура
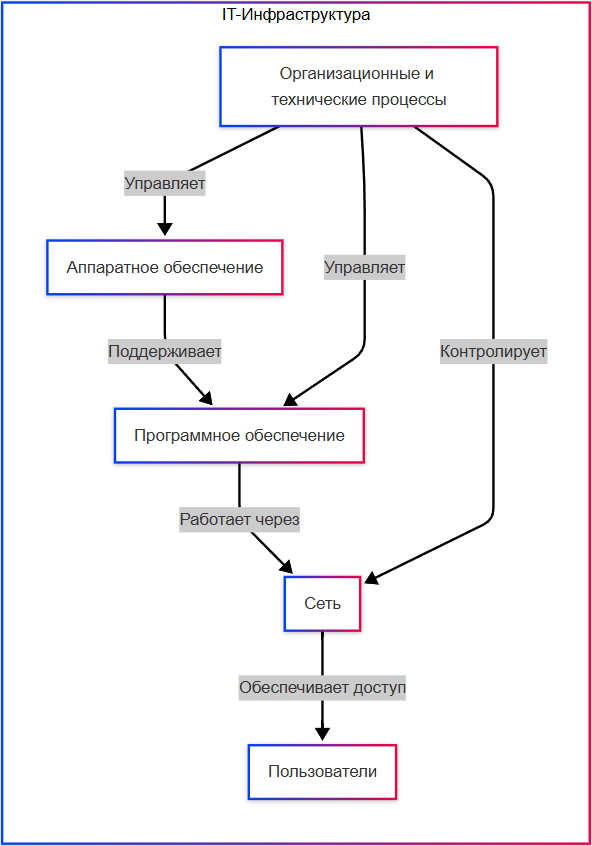
Инфраструктура в сфере информационных технологий представляет собой совокупность взаимосвязанных компонентов, обеспечивающих функционирование информационных систем на всех уровнях: от физического до прикладного. Она является основой, на которой строится работа современных организаций, независимо от их отраслевой принадлежности — будь то государственное учреждение, коммерческая компания или образовательная платформа. От надёжности, прозрачности и гибкости инфраструктуры напрямую зависят доступность сервисов, стабильность бизнес-процессов и эффективность взаимодействия пользователей с цифровой средой.
Системное администрирование рассматривает инфраструктуру как единую, управляемую экосистему, в которой каждый элемент имеет своё функциональное назначение и вклад в общий результат. Её структура иерархична, модульна и масштабируема: начиная с элементарной локальной сети в небольшом офисе и заканчивая распределёнными облачными платформами с географически разнесёнными центрами обработки данных. Важно подчеркнуть, что инфраструктура не ограничивается только техническими средствами — она включает также процедуры эксплуатации, политики безопасности, процессы резервного копирования, мониторинга и управления конфигурациями. Таким образом, инфраструктура — это организационные рамки, в которых они функционируют.
Что такое инфраструктура
Термин «инфраструктура» происходит от латинских infra — «ниже», «под» и structura — «строение», «устройство». В IT-контексте он обозначает базовую подсистему, поддерживающую работу высших уровней — прикладного программного обеспечения, сервисов, цифровых продуктов и пользовательских рабочих мест. Инфраструктура обеспечивает физическую и логическую связность всех элементов ИТ-ландшафта: она задаёт правила коммуникации, определяет маршруты передачи данных, управляет доступом к ресурсам и гарантирует целостность, конфиденциальность и доступность информации.
Современная ИТ-инфраструктура может быть реализована в одной из двух основных конфигураций: локальной (on-premises) или облачной. В локальном варианте все аппаратные и программные компоненты находятся в непосредственном распоряжении организации и размещаются на её территории — в серверной комнате, дата-центре или даже просто в шкафу с оборудованием. В облачной модели часть или вся инфраструктура предоставляется внешним поставщиком (например, AWS, Microsoft Azure, Yandex Cloud) через интернет в виде сервисов: вычислительных мощностей (IaaS), платформы (PaaS) или готовых приложений (SaaS). Гибридные и мультиоблачные подходы дополняют эти варианты, позволяя распределять нагрузку между собственными и арендованными ресурсами в зависимости от требований к производительности, стоимости и регуляторным ограничениям.
Однако, независимо от модели размещения, инфраструктура всегда состоит из пяти ключевых составляющих: аппаратного обеспечения, программного обеспечения, сетевой среды, пользователей и управляющих процессов. Рассмотрим каждую из них подробно.
Аппаратное обеспечение
Аппаратное обеспечение — это физическая основа инфраструктуры. К нему относятся все устройства, имеющие материальное воплощение и требующие электропитания для функционирования.
Центральным элементом в большинстве корпоративных сред остаётся сервер — специализированный компьютер, предназначенный для круглосуточной обработки запросов, хранения данных и выполнения служебных задач. В отличие от настольных ПК, серверы проектируются с учётом высокой отказоустойчивости: они оснащаются избыточными блоками питания, системами охлаждения, поддержкой ECC-памяти, RAID-массивами и возможностью «горячей» замены компонентов. Форм-факторы серверов варьируются от стоечных (rackmount), устанавливаемых в 19-дюймовые шкафы, до компактных blade-модулей и даже встраиваемых решений (например, на базе процессоров ARM для edge-вычислений).
Помимо серверов, к аппаратному обеспечению относятся:
- Сетевые устройства — маршрутизаторы, коммутаторы, межсетевые экраны (firewalls), точки беспроводного доступа (Wi-Fi AP). Они формируют транспортную основу, по которой передаются данные.
- Устройства хранения — как встроенные в серверы дисковые подсистемы, так и автономные решения: NAS (Network Attached Storage), SAN (Storage Area Network), гибридные и all-flash массивы.
- Периферийные устройства — принтеры, многофункциональные аппараты (МФУ), сканеры, терминалы, IP-телефоны, видеокамеры наблюдения. Несмотря на кажущуюся второстепенность, они интегрируются в общую схему: требуют IP-адресов, поддержки драйверов, учёта в системе управления активами и защиты от несанкционированного доступа.
- Клиентские устройства — рабочие станции (настольные ПК и ноутбуки), мобильные устройства (планшеты, смартфоны), тонкие клиенты и терминалы. Это точки входа пользователей в инфраструктуру.
Современные тенденции, такие как виртуализация и контейнеризация, не отменяют необходимости в физическом оборудовании — наоборот, они повышают требования к его характеристикам: к пропускной способности шины, количеству ядер процессора, объёму оперативной памяти и скорости дисковой подсистемы. Даже в облачных средах аппаратное обеспечение остаётся фундаментом — просто оно скрыто от конечного пользователя за абстракцией сервиса.
Программное обеспечение
Если аппаратное обеспечение — это тело инфраструктуры, то программное обеспечение — её нервная система. Без ПО железо остаётся набором нефункциональных компонентов.
Прежде всего, инфраструктуру обеспечивает операционная система — ядро, управляющее ресурсами и предоставляющее интерфейс для запуска приложений. В серверных средах доминируют Linux-дистрибутивы (Ubuntu Server, CentOS/Rocky Linux, Debian, openSUSE Leap) и Windows Server, хотя в узкоспециализированных сценариях применяются и другие ОС: FreeBSD, VMware ESXi (гипервизор), Proxmox VE (платформа виртуализации) или даже специализированные системы реального времени.
Над операционной системой размещаются сервисные компоненты:
- Системы виртуализации (Hyper-V, VMware vSphere, KVM, Xen) — позволяют запускать несколько изолированных виртуальных машин на одном физическом хосте.
- Системы управления конфигурациями (Ansible, Puppet, Chef, SaltStack) — обеспечивают идемпотентное развёртывание и поддержку состояния серверов.
- Средства мониторинга (Zabbix, Prometheus + Grafana, Nagios, Icinga) — отслеживают доступность, производительность и состояние компонентов.
- Системы резервного копирования и аварийного восстановления (Veeam, Bacula, BorgBackup, Rsync-на основе решений).
- Сервисы каталогов и аутентификации (Active Directory, FreeIPA, OpenLDAP), DNS-серверы (BIND, PowerDNS, Windows DNS), DHCP-серверы (ISC DHCPd, dnsmasq, встроенные в ОС реализации).
Отдельный пласт — прикладное программное обеспечение: СУБД (PostgreSQL, MySQL, Microsoft SQL Server, Oracle), веб-серверы (Nginx, Apache HTTP Server), платформы для разработки (Node.js, .NET, Java Runtime), системы управления проектами и документацией (Confluence, GitLab, Jira), а также корпоративные приложения: ERP, CRM, почтовые серверы (Postfix, Exim, Microsoft Exchange), системы электронного документооборота.
Программное обеспечение структурировано по уровням: от ядра ОС через системные демоны и службы до пользовательских приложений. Его управление включает установку, настройку, регулярное обновление, патчинг, лицензирование, аудит версий и поддержку жизненного цикла — от развёртывания до вывода из эксплуатации.
Сеть
Сеть — это ткань, связывающая всё остальное. Она обеспечивает транспорт данных между компонентами инфраструктуры и определяет, как, где и когда информация может быть передана.
На физическом уровне сеть строится на кабелях (витая пара Cat 5e/6/6a, оптоволокно OM3/OM4), беспроводных интерфейсах (Wi-Fi 5/6/6E, Bluetooth, LoRaWAN в промышленных сценариях), сетевых адаптерах и портах коммутаторов. На канальном уровне функционируют протоколы, такие как Ethernet, обеспечивающие доставку кадров внутри одного сегмента. На сетевом уровне доминирует IPv4 (и всё чаще IPv6), который предоставляет глобальную адресацию и маршрутизацию между подсетями.
Ключевыми устройствами сетевой инфраструктуры являются:
- Маршрутизатор (роутер) — устройство, принимающее решения о пересылке пакетов между разными сетевыми сегментами (например, между локальной сетью и интернетом). Он работает на третьем уровне модели OSI и использует таблицы маршрутизации для определения оптимального пути.
- Коммутатор (свитч) — устройство второго уровня, соединяющее узлы внутри одной подсети. Оно изучает MAC-адреса подключённых устройств и направляет трафик только туда, где он необходим (в отличие от устаревших концентраторов, транслирующих всё на все порты).
- Межсетевой экран (firewall) — фильтр, контролирующий входящий и исходящий трафик на основе правил безопасности. Современные firewalls (например, на базе pfSense, OPNsense, Cisco ASA, FortiGate) поддерживают фильтрацию по IP и портам, глубокую инспекцию трафика (DPI), защиту от вторжений (IDS/IPS), шейпинг пропускной способности.
Сетевая топология в типичной организации строится по иерархическому принципу: ядро — распределение — доступ. В небольшой компании эта иерархия может быть сведена к двум уровням: маршрутизатор (ядро + распределение) → коммутаторы доступа → пользовательские устройства.
Адресация в локальной сети, как правило, строится на основе частных (private) диапазонов IPv4, определённых в RFC 1918:
10.0.0.0—10.255.255.255(маска/8)172.16.0.0—172.31.255.255(/12)192.168.0.0—192.168.255.255(/16)
Наиболее распространённым выбором в малых и средних организациях является сеть 192.168.0.0/24, где доступно 254 адреса: от 192.168.0.1 до 192.168.0.254. В таком сегменте, как указано в ваших тезисах, маршрутизатору часто присваивается адрес 192.168.0.1, серверам — фиксированные адреса в начале диапазона (192.168.0.2–192.168.0.99), а клиентам — динамические адреса из пула DHCP (192.168.0.100–192.168.0.200). Такая схема упрощает управление: серверы всегда доступны по известному адресу, а клиенты автоматически получают параметры сети без ручной настройки.
Служба DHCP (Dynamic Host Configuration Protocol) играет критическую роль в автоматизации подключения устройств. При старте сетевого интерфейса клиент отправляет широковещательный запрос DHCPDISCOVER, маршрутизатор (или выделенный DHCP-сервер) отвечает предложением адреса (DHCPOFFER), клиент подтверждает (DHCPREQUEST), и сервер резервирует адрес на определённое время (lease time). При повторном подключении устройство пытается восстановить прежний адрес; если он занят, выдаётся новый. Фиксированные (статические) IP-адреса назначаются вручную или привязываются к MAC-адресу устройства через резервирование в DHCP-сервере — так называемые «привязки по hardware-адресу».
Важно понимать, что два устройства не могут иметь один и тот же IP-адрес в одной широковещательной области — это вызывает конфликт адресов, нарушает обмен данными и может привести к недоступности ресурсов. Именно поэтому при переносе устройства с фиксированным адресом в другую сеть требуется его переадресация — либо вручную, либо через автоматическое определение и исправление конфликта (например, механизм APIPA в Windows, выдающий адрес из 169.254.0.0/16, если DHCP недоступен).
Пользователи
Пользователи — это активные участники инфраструктуры, определяющие требования к функциональности, безопасности и удобству взаимодействия. В контексте системного администрирования пользователь — это идентифицированная сущность, обладающая уникальными учётными данными, правами доступа и профилем активности. Учётная запись пользователя может быть локальной (созданной непосредственно на конкретной машине) или централизованной (управляемой через службу каталогов, например, Active Directory или LDAP).
В современных организациях редко применяется подход «один пользователь — один аккаунт на одном ПК». Вместо этого используется концепция единой учётной записи, позволяющая человеку входить в систему с любого устройства, получать доступ к своим файлам, настройкам и приложениям в рамках выделенных прав. Такая модель снижает нагрузку на поддержку (не нужно дублировать учётные записи на каждом компьютере), упрощает аудит действий и повышает безопасность — например, при увольнении сотрудника достаточно отозвать доступ в одном месте.
Пользователи классифицируются по ролям (администратор, сотрудник отдела продаж, бухгалтер) и по типу доступа:
- Интерактивные пользователи — работают за рабочими станциями, запускают приложения, взаимодействуют с файловыми ресурсами.
- Сервисные учётные записи — не предназначены для входа в систему человеком. Используются для запуска служб, задач планировщика, подключения приложений к СУБД. Такие аккаунты должны иметь минимально необходимые привилегии (принцип наименьших привилегий) и регулярно проходить ревизию.
- Гостевые/анонимные пользователи — применяются в публичных системах (например, на веб-сайте или в точке доступа Wi-Fi). Обычно имеют крайне ограниченные права и изолируются от внутренних ресурсов.
Управление пользователями включает жизненный цикл: создание (onboarding), изменение прав (при смене должности), приостановку (в отпуске или на больничном), деактивацию (при уходе из компании). Автоматизация этого процесса достигается через интеграцию с HR-системами (например, через SCIM-протокол) или с помощью Identity & Access Management (IAM) платформ — как корпоративных (Microsoft Entra ID, Okta), так и open-source (Keycloak, FreeIPA).
Внутренняя инфраструктура компании
При построении локальной вычислительной сети в организации возникает необходимость определить, как будут организованы учётные записи, политики безопасности и доступ к общим ресурсам. Для этого существуют две фундаментальные модели: рабочая группа и домен.
Рабочая группа — это одноранговая (peer-to-peer) сеть, в которой все компьютеры равноправны. На каждом устройстве создаются локальные учётные записи, и для доступа к ресурсу на другом компьютере (например, к общей папке) пользователь должен знать имя и пароль учётной записи на том самом компьютере. Рабочая группа подходит для небольших коллективов (до 10–15 устройств), где нет необходимости в централизованном управлении, а администраторская нагрузка минимальна. Однако с ростом числа узлов управление становится неэффективным: смена пароля требует его обновления на всех машинах, политики безопасности невозможно применить единообразно, а аудит событий затруднён.
Домен — это клиент-серверная модель, в которой один или несколько серверов управляют централизованным каталогом пользователей, групп, политик и ресурсов. Все компьютеры в домене регистрируются в этом каталоге и доверяют ему в вопросах аутентификации и авторизации. Основное преимущество домена — единая точка управления. Администратор может:
- задать политику паролей (минимальная длина, срок действия, история),
- запретить запуск определённых программ,
- автоматически развернуть сетевые диски и принтеры,
- настроить единый профиль пользователя (роуминговый профиль),
- собирать журналы событий с всех узлов.
Переход от рабочей группы к домену — это шаг к зрелости ИТ-инфраструктуры. Он требует планирования: выбора имени домена (лучше избегать общепринятых имён вроде WORKGROUP или CORP), проектирования организационных единиц (OU), определения схемы делегирования прав.
Контроллер домена — основной сервер
Контроллер домена (Domain Controller, DC) — это сервер, на котором размещена служба каталогов (в экосистеме Microsoft — Active Directory Domain Services, AD DS; в Unix-подобных средах — FreeIPA или OpenLDAP с Kerberos и Samba в режиме DC). Его роль — быть источником доверия для всей доменной инфраструктуры.
Когда компьютер присоединяется к домену, он регистрируется в каталоге и получает копию учётных данных (в зашифрованном виде), необходимых для проверки подлинности. При входе пользователя на рабочую станцию имя и пароль не проверяются локально — запрос отправляется контроллеру домена. Если учётные данные корректны, сервер выдаёт билет (ticket) на основе протокола Kerberos, который затем используется для доступа к другим ресурсам без повторного ввода пароля (Single Sign-On, SSO).
Контроллер домена хранит базу данных каталога (в AD — это файл ntds.dit), содержащую:
- учётные записи пользователей и компьютеров,
- групповые объекты и членство в них,
- групповые политики (GPO — Group Policy Objects),
- схему каталога (определение типов объектов и их атрибутов),
- информацию о доверительных отношениях с другими доменами.
Важнейшая особенность контроллера домена — отказоустойчивость через репликацию. В реальной инфраструктуре никогда не используется единственный DC: как минимум два сервера настраиваются как контроллеры, и изменения в каталоге автоматически синхронизируются между ними. Это обеспечивает непрерывность работы даже при выходе одного из серверов из строя. Репликация может быть однонаправленной или двунаправленной, в пределах одного сайта или между географически удалёнными (site-to-site).
Для повышения безопасности контроллеры домена физически изолируются: к ним не подключаются пользователи напрямую, на них не устанавливаются прикладные приложения, а доступ администрирования строго регламентируется (например, через группу Domain Admins и механизм привилегированного доступа — PAM).
Схема построения
Технически, физическая и логическая топология инфраструктуры строится по принципу «от периферии к ядру». В типичном малом офисе сеть развёртывается по следующей цепочке:
Интернет → Маршрутизатор → (опционально: Firewall) → Коммутатор(ы) → Устройства
Маршрутизатор выполняет несколько функций одновременно:
- шлюз по умолчанию для локальных устройств,
- сервер DHCP и DNS (часто в упрощённых конфигурациях),
- NAT-устройство (преобразование частных адресов в публичный при выходе в интернет),
- точка беспроводного доступа (если встроена Wi-Fi антенна).
Коммутаторы добавляются для расширения количества портов. Они не имеют собственного IP-адреса в пользовательском сегменте (если не настроен VLAN-менеджмент или SNMP-мониторинг), и работают прозрачно — просто передают кадры между портами на основе MAC-таблицы. Современные управляемые коммутаторы поддерживают VLAN, QoS, портовую безопасность и агрегацию каналов (LACP), что позволяет строить более гибкие и безопасные сети даже в компактных масштабах.
Важно различать физическое подключение и логическую принадлежность. Устройства могут быть физически подключены к одному коммутатору, но находиться в разных виртуальных сетях (VLAN), изолированных друг от друга на уровне коммутации. Это позволяет, например, отделить трафик IoT-устройств (камер, умных розеток) от корпоративных рабочих станций без прокладки отдельных кабелей.
Хост и гости
Виртуализация — методологический подход к построению инфраструктуры. Она позволяет декомпозировать физические серверы на логические изолированные среды — виртуальные машины (ВМ), каждая из которых функционирует как самостоятельный компьютер.
Хост — это физический сервер с установленным гипервизором (например, VMware ESXi, Microsoft Hyper-V, KVM на базе Linux). Гипервизор управляет доступом виртуальных машин к CPU, памяти, дисковым и сетевым ресурсам. Он создаёт виртуальные устройства (vCPU, vRAM, vNIC, vHDD), которые отображаются в гостевой ОС как реальные.
Гость — это виртуальная машина, запущенная на хосте. У неё есть собственная операционная система, IP-адрес, учётные записи и приложения. С точки зрения сети и пользователя гость неотличим от физического сервера — разве что по некоторым признакам (например, определённым драйверам или отсутствию TPM в старых версиях).
Преимущества виртуализации в инфраструктуре:
- Консолидация: несколько серверных ролей (контроллер домена, файловый сервер, веб-сервер) могут работать на одном физическом хосте, что снижает потребление энергии, занимаемое пространство и стоимость обслуживания.
- Изоляция: сбой в одной ВМ не влияет на другие (если не исчерпаны общие ресурсы хоста).
- Мобильность: ВМ можно легко переместить между хостами (vMotion, Live Migration), что упрощает обслуживание «железа» без простоя сервисов.
- Мгновенное развёртывание: клонирование шаблона позволяет создать новую среду за минуты, а не часы.
Виртуализация лежит в основе современных подходов к построению инфраструктуры — от частных облаков (на базе vSphere или OpenStack) до платформ контейнеризации (где гипервизор заменяется на runtime вроде containerd, а «гости» — на контейнеры). Однако важно понимать: виртуализация добавляет слой абстракции, но не отменяет необходимости в грамотном проектировании сетей, хранилищ и резервирования.
Хранилища
Хранилище данных — это критически важный компонент, определяющий доступность, целостность и производительность информационных систем. Инфраструктура может использовать несколько типов хранилищ в зависимости от задач:
- Локальные диски — прямое подключение к серверу (SATA, SAS, NVMe). Просты в настройке, но не масштабируемы и не обеспечивают отказоустойчивости без RAID.
- NAS (Network Attached Storage) — файловый сервер, доступный по протоколам SMB/CIFS (Windows) или NFS (Unix/Linux). Обычно используется для общих папок, резервных копий, медиафайлов. Относительно недорог, прост в управлении, но может стать узким местом при высокой нагрузке.
- SAN (Storage Area Network) — блочное хранилище, подключаемое через Fibre Channel или iSCSI. Представляется серверу как локальный диск, что позволяет использовать его для кластерных файловых систем (например, VMFS в vSphere) и баз данных с высокими требованиями к IOPS и задержкам.
- Объектное хранилище — используется в облачных средах (S3-совместимые интерфейсы). Оптимально для неструктурированных данных: архивов, логов, мультимедиа.
Выбор типа хранилища зависит от трёх ключевых параметров: ёмкость, производительность (IOPS, latency) и надёжность (RAID-уровень, репликация, резервирование питания и контроллеров). Например, для контроллера домена с небольшой AD-базой достаточно RAID 1 на SAS-дисках; для СУБД с высокой интенсивностью записи — RAID 10 на SSD в SAN; для архива документов — масштабируемый NAS с дедупликацией и шифрованием.
DEV / TEST / PREPROD / PROD — уровни окружений
Инфраструктура не существует в одном экземпляре. Для обеспечения стабильности и безопасности бизнес-процессов она разделяется на логические уровни окружений, каждое из которых служит определённой цели в жизненном цикле разработки и эксплуатации программного обеспечения.
- DEV (Development) — среда разработки. Здесь программисты пишут, отлаживают и локально тестируют код. Как правило, наименее формализована: может работать на локальных машинах, в контейнерах (Docker) или на выделенных серверах. Данные — тестовые или анонимизированные копии.
- TEST (Testing) — среда для функционального, интеграционного и регрессионного тестирования. Здесь QA-инженеры проверяют соответствие требованиям, проводят нагрузочное тестирование. Окружение максимально приближено к production по конфигурации, но изолировано от реальных данных и пользователей.
- PREPROD (Pre-Production / Staging) — зеркало production среды, включая актуальные данные (часто — свежую копию, прошедшую анонимизацию), ту же версию ОС, ПО, патчей и настроек. Используется для финальной проверки перед выкатом: тестирования развёртывания, миграции базы, взаимодействия с внешними системами. Доступ к нему строго регламентирован.
- PROD (Production) — боевая, эксплуатационная среда. Здесь работают реальные пользователи, обрабатываются финансовые операции, хранятся персональные данные. Любое изменение в PROD требует предварительного тестирования, согласования, резервной копии и отката. Применяются максимальные меры безопасности: WAF, DDoS-защита, аудит, мониторинг в реальном времени.
Разделение окружений предотвращает катастрофические ошибки: баг, обнаруженный на этапе TEST, не выведет из строя рабочий сайт. Оно также поддерживает принцип «инфраструктура как код» (IaC): конфигурации всех уровней описываются в шаблонах (Terraform, Ansible), что гарантирует их идентичность и воспроизводимость.
Узлы и устройства
Термин узел (node) в сетевой теории означает любое устройство, способное отправлять, принимать или пересылать данные в сети. Это — самое широкое понятие: узлом может быть:
- сервер (физический или виртуальный),
- рабочая станция,
- ноутбук,
- смартфон,
- принтер или МФУ с сетевым интерфейсом,
- IP-камера,
- IoT-датчик,
- маршрутизатор, коммутатор, межсетевой экран (если они имеют IP-интерфейс для управления),
- виртуальный маршрутизатор или балансировщик (например, HAProxy в контейнере).
Таким образом, сеть — это граф, где узлы соединены линиями связи (физическими или логическими). Узлы могут быть статическими (серверы с фиксированными IP) или динамическими (мобильные устройства, подключающиеся и отключающиеся). Каждый узел должен быть учтён в системе управления активами (CMDB) и иметь уникальный идентификатор — не обязательно IP (он может меняться), но, например, MAC-адрес, серийный номер или хэш от конфигурации.
Устройства — это конкретные экземпляры узлов, классифицируемые по функциональному назначению:
- МФУ и принтеры — требуют драйверов, учёта печати (print auditing), ограничений по квотам и безопасности (например, печать по PIN-коду).
- NAS-серверы — полноценные вычислительные системы с ОС (часто Linux-based), поддержкой RAID, репликации, шифрования и API для интеграции.
- Коммутаторы и роутеры — даже неуправляемые модели сегодня имеют веб-интерфейс или Telnet/SSH для базовой настройки. Управляемые устройства поддерживают VLAN, STP, портовую агрегацию, ACL — и требуют регулярного обновления прошивки.
Каждое устройство в инфраструктуре должно быть:
- учтено (инвентаризация),
- настроено в соответствии с политиками,
- включено в систему мониторинга,
- защищено от несанкционированного доступа (отключение ненужных служб, смена заводских паролей, сегментация сети),
- документировано (местоположение, контактное лицо, схема подключения, резервные копии конфигурации).
Проектирование инфраструктуры
Проектирование инфраструктуры — это системная инженерная задача, требующая анализа бизнес-целей, оценки рисков и прогнозирования развития. Оно начинается задолго до закупки первого сервера и включает несколько строго выделенных фаз.
Анализ требований — определяет, зачем нужна инфраструктура. Здесь собираются данные о:
- количестве и типе пользователей (офисные сотрудники, удалённые работники, клиенты),
- критичности сервисов (SLA: 99.9 %, 99.99 %, 99.999 %),
- объёмах и типах данных (структурированные транзакции, неструктурированные логи, медиа),
- регуляторных ограничениях (ФЗ-152, GDPR, PCI DSS — где могут храниться данные, какие шифровальные алгоритмы допустимы),
- бюджете и сроках развёртывания.
На основе этого формируется техническое задание, которое задаёт конкретные параметры: минимальная пропускная способность магистрали — 1 Гбит/с, время восстановления после сбоя (RTO) — не более 4 часов, максимальный объём резервной копии — 10 ТБ в сутки.
Архитектурное проектирование переводит требования в схемы:
- логическая топология (какие подсети, VLAN, зоны безопасности),
- физическая схема (шкафы, кабельные трассы, точки подключения),
- распределение ролей (какие функции возьмёт на себя каждый сервер),
- стратегия резервирования (активно-активный кластер, горячий резерв, репликация в удалённый ЦОД).
Важнейший документ на этом этапе — диаграмма развёртывания (deployment diagram), отражающая соответствие программных компонентов аппаратным узлам. Она учитывает текущее состояние и запас по масштабируемости: например, резервные слоты в сервере под дополнительные диски, порты коммутатора с запасом на 30 %, возможность добавления второго контроллера домена без переконфигурации сети.
Документирование — неотъемлемая часть проектирования. Инфраструктурная документация включает:
- спецификации оборудования (модель, серийный номер, гарантия),
- схемы сетей с указанием IP-диапазонов, VLAN ID, масок,
- конфигурационные файлы с аннотациями (почему выбран тот или иной параметр),
- инструкции по восстановлению (runbooks),
- матрицы ответственности (кто вносит изменения, кто утверждает, кто тестирует).
Хорошо задокументированная инфраструктура снижает зависимость от конкретных сотрудников и ускоряет реакцию на инциденты. В профессиональной практике недокументированная конфигурация приравнивается к неподтверждённой — её нельзя считать валидной.
Жизненный цикл инфраструктурных компонентов
Каждый элемент инфраструктуры проходит через чётко определённые стадии, образующие его жизненный цикл. Управление этим циклом — ключевая задача системного администратора, особенно в условиях ограниченного бюджета и устаревающего оборудования.
-
Планирование и закупка
Выбор модели оборудования (новое, б/у, refurbished), поставщика, условий поддержки (SLA на ремонт, NBD-доставка запчастей). Важно учитывать стоимость приобретения, TCO (Total Cost of Ownership) — расходы на электроэнергию, охлаждение, обслуживание, лицензии. -
Развёртывание и ввод в эксплуатацию
Физическая установка, первичная настройка (IP, имя хоста, время), интеграция в систему мониторинга и CMDB. На этом этапе формируется «базовая конфигурация» — эталонное состояние, от которого будут отсчитываться все последующие изменения. -
Эксплуатация
Период активного использования. Сюда входят:- регулярные обновления ПО и микрокода,
- мониторинг состояния (температура, SMART-статус дисков, загрузка CPU),
- управление инцидентами и запросами,
- аудит конфигураций на соответствие политикам.
-
Обновление и модернизация
Не всегда означает замену «железа». Может включать:- апгрейд памяти или дисков,
- переход на новую версию ОС (например, Windows Server 2016 → 2022),
- миграцию ролей на другие серверы (например, вынос контроллера домена с устаревшего хоста),
- виртуализацию физического сервера (P2V).
-
Вывод из эксплуатации
Самый ответственный этап. Требует:- полного резервного копирования конфигураций и данных,
- деактивации учётных записей и служб,
- физической очистки носителей (санкционированное стирание, физическое уничтожение),
- актуализации документации (пометка «выведен», дата, причина).
Нарушение порядка жизненного цикла — например, пропуск этапа документирования при развёртывании или пренебрежение очисткой дисков при утилизации — создаёт риски для безопасности и стабильности всей инфраструктуры.
Мониторинг и логирование как неотъемлемые части инфраструктуры
Мониторинг и логирование — это «органы чувств» инфраструктуры. Без них невозможно поддерживать её в рабочем состоянии, так как первые признаки сбоя часто проявляются задолго до полной остановки сервиса.
Мониторинг — это непрерывный сбор метрик о состоянии компонентов. Он бывает:
- инфраструктурным: загрузка CPU, объём свободной памяти, использование дискового пространства, пропускная способность интерфейса;
- сервисным: время отклика веб-сервера, количество подключений к СУБД, статус служб;
- бизнес-уровня: количество обработанных заказов в минуту, время оформления заявки.
Современные системы мониторинга (например, Prometheus + Grafana) работают по принципу pull-модели: сервер периодически опрашивает экспортёры на узлах. Это обеспечивает предсказуемую нагрузку и единообразие сбора данных. Пороговые значения (alert rules) настраиваются на динамику: резкий рост потребления памяти за 5 минут, падение числа успешных запросов относительно среднего за неделю.
Логирование — это запись событий, происходящих в системе. В отличие от метрик, логи содержат контекст: кто, что, когда и почему. Ключевые требования к логированию:
- централизация (все логи поступают в единое хранилище — ELK-стек, Graylog, Loki),
- нормализация формата (например, JSON с обязательными полями:
timestamp,host,service,level,message), - сохранение целостности (логи должны быть неизменяемыми после записи — например, через WORM-хранилища),
- ретеншн-политики (сколько дней хранить: 30 для отладки, 180 для аудита, 5 лет для регуляторных требований).
Комбинация мониторинга и логирования позволяет реагировать на сбои, проводить постмортем-анализ (post-mortem): восстановить цепочку событий, выявить корневую причину и внедрить меры предотвращения.
Безопасность на уровне инфраструктуры
Безопасность не может быть «добавлена сверху» — она должна быть заложена в архитектуру инфраструктуры с самого начала. Основные принципы:
Сетевая сегментация — разделение инфраструктуры на зоны с разным уровнем доверия:
- внутренняя сеть (доступна только авторизованным сотрудникам),
- сеть DMZ (Demilitarized Zone) — для публичных сервисов (веб-сервера, почтовые шлюзы), изолированная от внутренней,
- сеть управления — отдельный VLAN для доступа к консольным портам, IPMI, SNMP,
- гостевая сеть Wi-Fi — полностью изолированная от корпоративных ресурсов.
Между зонами устанавливаются межсетевые экраны с чёткими правилами: разрешено только то, что необходимо для работы (принцип «запрещено всё, кроме явно разрешённого»).
Минимизация attack surface — сокращение потенциальных точек атаки:
- отключение неиспользуемых служб (FTP, Telnet, SMBv1),
- удаление учётных записей по умолчанию,
- ограничение физического доступа к серверам (шкафы с замками, видеонаблюдение),
- использование защищённых протоколов (SSH вместо Telnet, HTTPS вместо HTTP, LDAPS вместо LDAP).
Управление доступом:
- многофакторная аутентификация (MFA) для администраторов,
- привилегированный доступ по требованию (just-in-time, JIT),
- аудит всех действий с повышенными правами.
Инфраструктурная безопасность — это непрерывный процесс: регулярные сканирования уязвимостей (Nessus, OpenVAS), пентесты, обновление политик в соответствии с новыми угрозами.
Облачная инфраструктура
Облачная инфраструктура не отменяет фундаментальных принципов, но изменяет их реализацию. Вместо закупки серверов организация арендует вычислительные ресурсы, хранилище и сеть у провайдера (IaaS — Infrastructure as a Service). Однако ответственность за их использование остаётся у клиента — это выражается в модели разделения ответственности (Shared Responsibility Model).
Например, в Amazon Web Services:
- AWS отвечает за физическую безопасность ЦОД, питание, охлаждение, гипервизор.
- Клиент отвечает за ОС, настройку сети, управление учётными записями, обновление ПО, защиту данных.
Ключевые особенности облачной инфраструктуры:
- Эластичность — возможность мгновенно масштабировать ресурсы вверх или вниз в зависимости от нагрузки (автоматическое масштабирование на основе метрик).
- Самообслуживание — развёртывание нового сервера через API или веб-интерфейс за минуты, без участия поставщика.
- Оплата по потреблению — модель pay-as-you-go делает капитальные затраты (CapEx) операционными (OpEx).
Гибридная инфраструктура сочетает локальные и облачные компоненты. Типичные сценарии:
- Облачный бэкап — резервные копии локальных серверов отправляются в облако для защиты от локальных катастроф.
- Вынос пиковых нагрузок — в периоды высокой активности (например, распродажа) часть трафика направляется в облако (cloud bursting).
- Размещение чувствительных данных локально, а публичных — в облаке — компромисс между безопасностью и удобством.
Для связи локальной и облачной частей используются выделенные каналы (Direct Connect, ExpressRoute) или зашифрованные VPN-туннели. Критически важно обеспечить единый каталог пользователей (например, через федерацию с Entra ID) и сквозной мониторинг.